Prometheus est une solution modulaire, se situant à mi-chemin entre supervision et métrologie.
Plus qu’un simple logiciel, l’écosystème Prometheus regroupe plusieurs composantes complémentaires, écrites principalement en Go. Orienté cloud, il facilitera la supervision de clusters Kubernetes, Docker Swarm, ou clouds publiques. Polyvalent, il saura collecter ses métriques depuis tout type de service ou équipement.
À l’origine produit par SoundCloud, Prometheus est aujourd’hui un projet open source, maintenu par la communauté.

Les composantes de Prometheus
Prometheus Server
Le serveur Prometheus aura pour fonction d’interroger les services que l’on souhaite superviser, collectant leurs métriques à intervalle régulier, et les stockant dans un volume local, au format TSDB — proche de l’OpenTSDB.
À ce titre, le serveur Prometheus en lui-même est d’abord une solution de métrologie : sa première fonction sera d’agréger différentes séries chronologiques, pour les présenter à ses clients, par l’intermédiaire d’un GUI web minimaliste quoi qu’efficace, et d’une API restful. Nous reviendrons dans un instant l’aspect supervision, celui-ci impliquant une autre brique de l’écosystème Prometheus.
Pour tester Prometheus, nous pourrions utiliser Docker. Commencer par créer un fichier de configuration minimaliste, tel que Prometheus interroge ses propres métriques :

$ cat <<EOF >prom-demo.yaml
global:
scrape_interval: 10s
evaluation_interval: 10s
#rule_files:
#- /etc/prometheus/rules.d/*.yaml
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
#alerting:
# alertmanagers:
# - scheme: http
# static_configs:
# - targets:
# - 1.2.3.4:9093
EOF
Nous rattacherons ensuite ce fichier à un conteneur, en nous appuyant sur l’image Prometheus officielle :
$ docker run -p9090:9090 --mount type=bind,source=`pwd`/prom-demo.yaml,destination=/etc/prometheus/prometheus.yml -it prom/prometheus
Unable to find image 'prom/prometheus:latest' locally
latest: Pulling from prom/prometheus
...
level=info ts=2020-08-28T09:16:23.740Z caller=main.go:308 msg="No time or size retention was set so using the default time retention" duration=15d
level=info ts=2020-08-28T09:16:23.740Z caller=main.go:343 msg="Starting Prometheus" version="(version=2.20.1, branch=HEAD, revision=983ebb4a513302315a8117932ab832815f85e3d2)"
...
level=info ts=2020-08-28T09:16:23.741Z caller=main.go:684 msg="Starting TSDB ..."
...
level=info ts=2020-08-28T09:16:23.746Z caller=main.go:701 msg="TSDB started"
level=info ts=2020-08-28T09:16:23.746Z caller=main.go:805 msg="Loading configuration file" filename=/etc/prometheus/prometheus.yml
level=info ts=2020-08-28T09:16:23.747Z caller=main.go:833 msg="Completed loading of configuration file" filename=/etc/prometheus/prometheus.yml
level=info ts=2020-08-28T09:16:23.747Z caller=main.go:652 msg="Server is ready to receive web requests."
Nous pourrons alors nous connecter à l’interface web de Prometheus : http://localhost:9090
D’ici, nous sommes en mesure d’interroger la base de Prometheus, qui ne comporte pour l’instant que les métriques internes du serveur Prometheus :
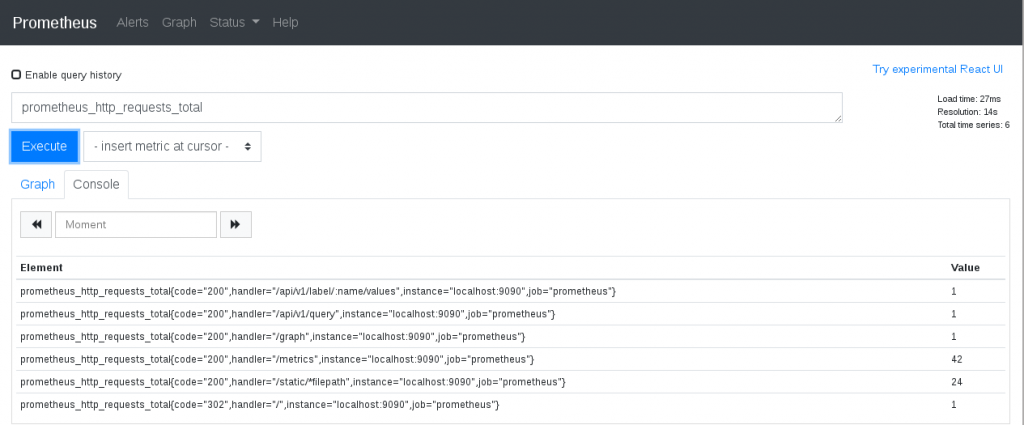 Premières métriques collectées par Prometheus {: .text-center}
Premières métriques collectées par Prometheus {: .text-center}
Prometheus implémente son propre langage de requête, le PromQL – Prometheus Query Language – permettant la sélection et l’aggrégation de ses métriques.
Au plus simple, nous pouvons demander les points associés à une série, sélectionner certaines métriques fonctions de labels, effectuer des opérations arithmétiques.
PromQL offre également une foule de fonctions, allant du calcul de moyenne, aux ré-écritures de labels, tri, groupement par critères, …
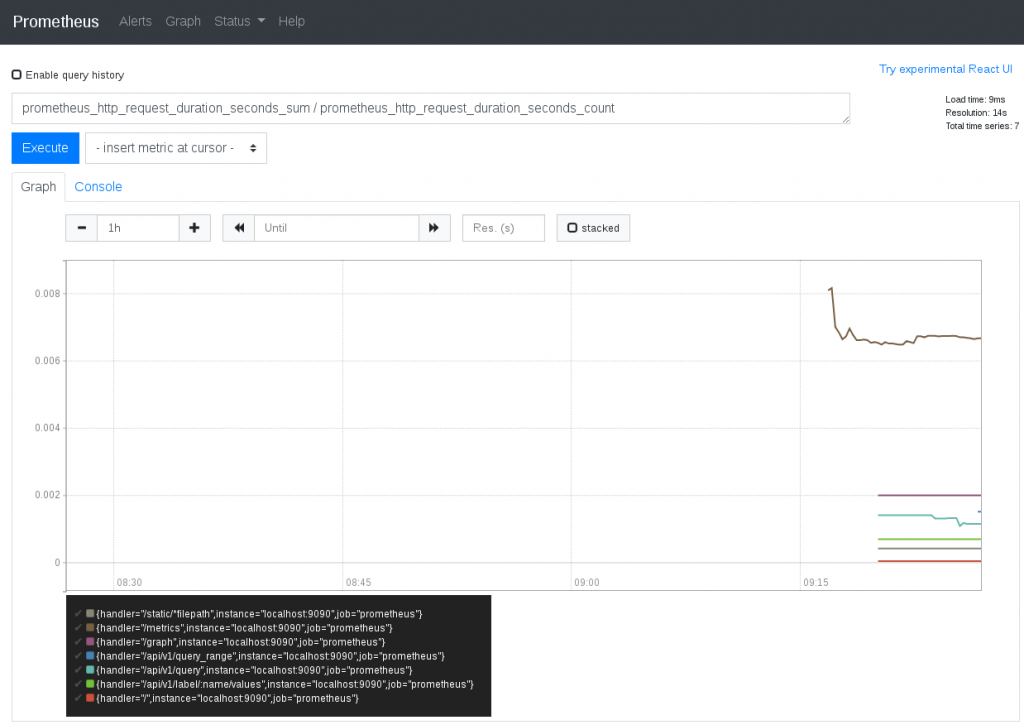
La simplicité du serveur Prometheus le rend particulièrement résilient, et pourra en faire un atout de taille dans le diagnostique d’incidents.
Revenons maintenant sur la facette supervision du serveur Prometheus. Notre exemple de configuration précédant mentionne un bloc rule_files, optionnel. Prometheus peut y inclure une liste de règles, s’appuyant sur des requêtes PromQL. Interrogeant les enregistrements locaux, elles pourront identifier les situations inhabituelles, et lever une alerte. L’exemple suivant s’intéresse à Apache :
groups:
- name: ApacheRulesGroup
rules:
- alert: ApacheRestart
expr: apache_uptime_seconds_total / 60 < 1
for: 5m
labels:
severity: warning
annotations:
summary: "Apache restart (instance {{ $labels.instance }})"
description: "Apache has just been restarted, less than one minute ago.\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: ApacheWorkersLoad
expr: (sum by (instance) (apache_workers{state="busy"}) / sum by (instance) (apache_scoreboard) ) * 100 > 80
for: 5m
labels:
severity: critical
annotations:
summary: "Apache workers load (instance {{ $labels.instance }})"
description: "Apache workers in busy state approach the max workers count 80% workers busy on {{ $labels.instance }}\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
Ici, nous pourrons citer le site Awesome Prometheus Alerts, proposant une base de règles constituant un bon point de départ.
Cependant, si Prometheus sait dire quelles sondes sont en erreur à un instant T, c’est traditionnellement l’AlertManager, qui sera en charge de retransmettre l’information.
AlertManager
L’AlertManager est un autre service, membre à part entière de l’écosystème Prometheus. Sa fonction se limite à l’émission d’alertes, contrôlant les délais avant première notification, éventuelles répétitions, ou medium d’alerte – traditionnellement mail ou notification HTTP, voire intégration avec une API. Le serveur Prometheus publie des alertes fonction de ses règles, l’AlertManager détermine lesquelles doivent donner lieu à notification.
Dans le contexte d’un déploiement hautement disponible, au moins deux serveurs Prometheus collecteront leurs métriques et évalueront leurs règles indépendamment. L’AlertManager devant alors s’assurer de ne pas envoyer de notification en double. Le service AlertManager peut lui aussi être distribué. Les membres d’un même déploiement fonctionnant alors en cluster, toujours pour éviter la répétition d’une même notification. Si une panne matérielle devait impacter une instance Prometheus ou AlertManager, ni la retransmission d’alertes, ni la collection de métriques ou l’évaluation de règles n’en souffriraient.
La configuration de l’AlertManager se contente de définir une liste de destinataires (receivers), et règles de diffusion (routes) :
$ cat <<EOF am-demo.yaml
global:
smtp_smarthost: localhost:25
smtp_from: alertmanager@demo.lan
route:
receiver: default
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
group_by:
routes:
- match:
severity: critical
receiver: default
repeat_interval: 1h
- match:
severity: warning
receiver: default
receivers:
- name: default
email_configs:
- to: root@demo.local
EOF
Nous pouvons lancer un AlertManager, chargeant cet exemple de configuration :
$ docker run -p9093:9093 --mount type=bind,source=`pwd`/am-demo.yaml,destination=/etc/config/alertmanager.yml prom/alertmanager --config.file=/etc/config/alertmanager.yml
Unable to find image 'prom/alertmanager:latest' locally
latest: Pulling from prom/alertmanager
...
level=info ts=2020-08-28T09:59:33.284Z caller=main.go:216 msg="Starting Alertmanager" version="(version=0.21.0, branch=HEAD, revision=4c6c03ebfe21009c546e4d1e9b92c371d67c021d)"
level=info ts=2020-08-28T09:59:33.284Z caller=main.go:217 build_context="(go=go1.14.4, user=root@dee35927357f, date=20200617-08:54:02)"
level=info ts=2020-08-28T09:59:33.285Z caller=cluster.go:161 component=cluster msg="setting advertise address explicitly" addr=172.17.0.3 port=9094
level=info ts=2020-08-28T09:59:33.285Z caller=cluster.go:623 component=cluster msg="Waiting for gossip to settle..." interval=2s
level=info ts=2020-08-28T09:59:33.304Z caller=coordinator.go:119 component=configuration msg="Loading configuration file" file=/etc/config/alertmanager.yml
level=info ts=2020-08-28T09:59:33.304Z caller=coordinator.go:131 component=configuration msg="Completed loading of configuration file" file=/etc/config/alertmanager.yml
level=info ts=2020-08-28T09:59:33.306Z caller=main.go:485 msg=Listening address=:9093
level=info ts=2020-08-28T09:59:35.286Z caller=cluster.go:648 component=cluster msg="gossip not settled" polls=0 before=0 now=1 elapsed=2.000042016s
Pour que Prometheus communique avec notre AlertManager, nous devrons modifier la configuration du serveur Prometheus, dé-commenter le bloc alerting, en renseignant l’addresse du service AlertManager.
Exporters
Un exporter peut prendre plusieurs formes. Son rôle sera d’exposer des métriques, système ou applicatives. Tout comme l’agent NRPE que l’on utiliserait dans une solution de supervision apparentée à Nagios, un exporter est un agent, auquel Prometheus se connectera à intervalle régulier, interrogeant l’état du service.
Le plus souvent, un exporter consiste en un processus, implémentant un serveur HTTP. L’exporter pourra regrouper des métriques locales (occupation disque, utilisation CPU, réseau, … par exemple netdata), ou se connecter à un service externe (base MySQL, Redis, … par exemple un exporter Apache), collectant des métriques applicatives, pour les présenter à Prometheus. Certaines applications s’intègreront nativement à Prometheus, par exemple Ceph ou CodiMD, celles-ci pouvant exposer leurs métriques au format voulu.
Plusieurs libraries existent, facilitant l’écriture d’exporters en Go, Java, Python, Node.JS, Perl, … et l’exposition de vos propres métriques applicatives. Si l’on trouve foule d’exporters, pour les solutions open-source populaires notamment, parfois nous devrons composer avec des produits n’offrant pas ou peu de métriques. Ici, le projet Prometheus propose un Blackbox Exporter, pouvant produire des compteurs, fonctions de checks HTTP, TCP, DNS, ICMP, … Reproduisant les classiques d’un outil de supervision plus traditionnel.
Exporters comme librairies : si certains sont fournis dans le cadre du projet Prometheus, ils font encore exception. L’écosystème Prometheus est relativement jeune, l’exhaustivité, ou le niveau de complétion, de fiabilité et de qualité de ses exporters communautaires reste variable, si on les compare aux alternatives Nagios ou Collectd. La supervision d’une infrastructure consistera en bonne partie en la rédaction de règles Prometheus, et donc dans le choix de nos exporters.
Dans un contexte Kubernetes ou OpenShift, en complément d’exporters applicatifs, nous pourrions configurer la collection des métriques du cluster en nous appuyant sur : – le node-exporter fourni par Prometheus – l’exporter kube-state-metrics du projet Kubernetes – les métriques servies par l’agent Kubelet
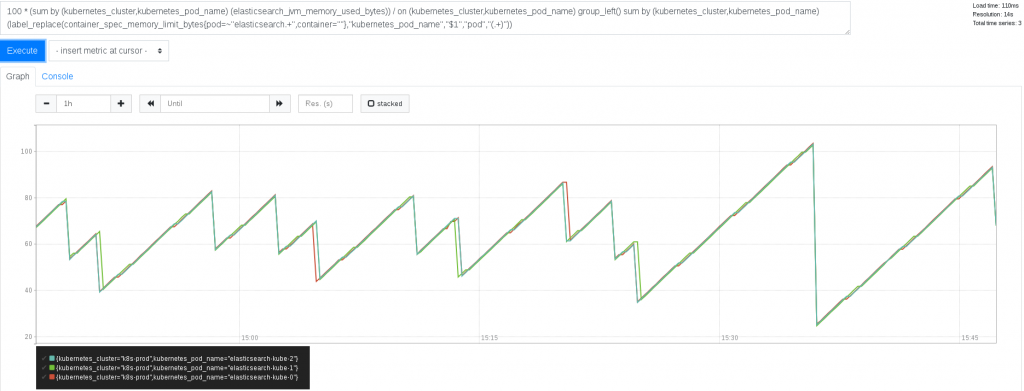
Dans l’exemple précédent, nous pouvons mettre en relation une métrique renvoyée par un exporter ElasticSearch, à une autre qui nous vient de l’API Kubernetes, visualisant alors l’espace mémoire occupé par plusieurs JVM, fonction de l’espace alloué à leur déploiement respectif. De tels croisements seront souvent nécessaires, les exporters se focalisant traditionnellement sur une application, ou un système.
Prometheus Push Gateway
Quand l’interrogation de métriques depuis Prometheus n’est pas possible, l’utilisation d’une Prometheus Push Gateway est envisageable. Nos applications pourront alors y pousser leurs séries. D’une certaine manière, nous pourrions rapprocher le fonctionnement d’une Push Gateway à celui de Statsd.
Le service Prometheus Push Gateway pourra addresser les cas particuliers, en dehors desquels son utilisation n’est généralement pas recommandée. Une alternative pouvant être l’utilisation d’une fédération, dont l’un des membres se trouvera dans le réseau autrement inaccessible.
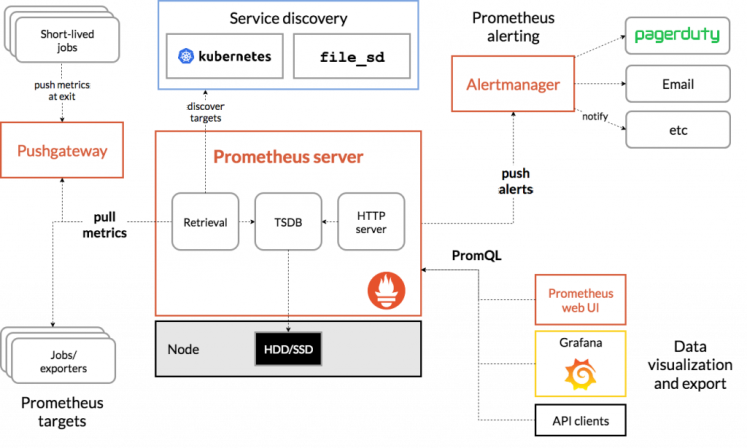
Architecture Prometheus + PushGateway + AlertManager
Fédération Prometheus
Au delà de la collection de métriques depuis de simples exporters, un serveur Prometheus pourra importer ses données depuis une autre instance Prometheus. Il est ainsi possible d’aggréger les séries de plusieurs déploiements Prometheus, supervisant diverses infrastructures.
Le prometheus.yml du serveur central pourra, comme dans l’exemple suivant, interroger d’autres serveurs Prometheus, intégrant alors leurs séries fonction d’une liste de filtres :
scrape_configs:
- job_name: my-fed-job
basic_auth:
password: optional-auth-secret
username: optional-auth-userr
honor_labels: true
metrics_path: /federate
params:
'match[]':
- '{job="metrics-from-that-job"}'
- '{kubernetes_cluster=~"metrics-from-cluster-(one|too)"}'
scheme: https
scrape_interval: 15s
scrape_timeout: 10s
static_configs:
- targets:
- remote-prometheus0.dc0.example.com:443
- remote-prometheus1.dc1.example.com:443
tls_config:
insecure_skip_verify: false
- job_name: ...
...
Notons que cette fonctionnalité n’est pas toujours pertinente du point de vue de la supervision – rajoutant des intermédiaires, et donc un risque de perdre une alerte. À moins d’un contexte empêchant l’émission de notifications depuis certains Prometheus, mieux vaudra multiplier les déploiements d’AlertManagers.
En ce qui concerne la métrologie, la fédération simplifie grandement la mise en relation ou la comparaison de données entre plusieurs entités autrement indépendantes.
En revanche, le volume de métriques collectées aura un impact significatif sur la consommation de ressources du serveur Prometheus – en particulier mémoire et disque.
Si l’on devait perdre son contrôle, nous pourrions considerer l’augmentation du scrape_interval, voire le retrait de certains labels qui pourraient être inutiles ou redondants – quoi que de telles optimisations n’aient qu’un impact limité. Sans doute voudra-ton réduire la rétention d’instances Prometheus en périphérie de la fédération. La chose ne sera pas toujours souhaitable en son centre.
Suivant le contexte, pourra se poser la question de Thanos, sur lequel nous reviendrons dans un instant. La fédération reste un bon candidat, tant que l’on peut allouer à Prometheus suffisamment de mémoire.
Quelques Produits s’intègrant à Prometheus
Grafana
Grafana est une application web permettant la visualisation de données, s’interfaçant avec diverses bases et APIs. Cette solution ne fait pas partie du projet Prometheus, mais s’intègrera parfaitement à ce dernier.
Grafana simplifie la configuration, l’édition et le partage de dashboards, s’appuyant sur les métriques collectées par diverses solutions de métrologies.
Dans certains cas, Grafana pourra également émettre des notifications, fonction d’alertes que nous aurions configuré. Mais comme évoqué précédemment, dans le contexte de Prometheus, l’AlertManager remplit déjà ce rôle. L’émission d’alertes par Grafana pouvant rester pertinent, par exemple lorsque les utilisateurs finaux ne disposent d’un moyen d’édition de leurs règles et seuils d’alerte, dans la configuration de Prometheus. Au besoin, Grafana saura s’interfacer avec un déploiement d’AlertManager.
Pour lancer un conteneur de test :
$ docker run -p3000:3000 -it grafana/grafana
Unable to find image 'grafana/grafana:latest' locally
latest: Pulling from grafana/grafana
...
t=2020-08-28T10:54:09+0000 lvl=info msg="Starting Grafana" logger=server version=7.1.5 commit=9893b8c53d branch=HEAD compiled=2020-08-25T08:27:17+0000
t=2020-08-28T10:54:09+0000 lvl=info msg="Config loaded from" logger=settings file=/usr/share/grafana/conf/defaults.ini
t=2020-08-28T10:54:09+0000 lvl=info msg="Config loaded from" logger=settings file=/etc/grafana/grafana.ini
...
Se connecter à Grafana, http://localhost:3000, et s’identifier avec le compte par défaut : admin / admin.
Cliquer sur “Add your first data source“. Puis sur “Prometheus“:
 }
}
Renseigner l’addresse du serveur Prometheus, et sauvegarder :
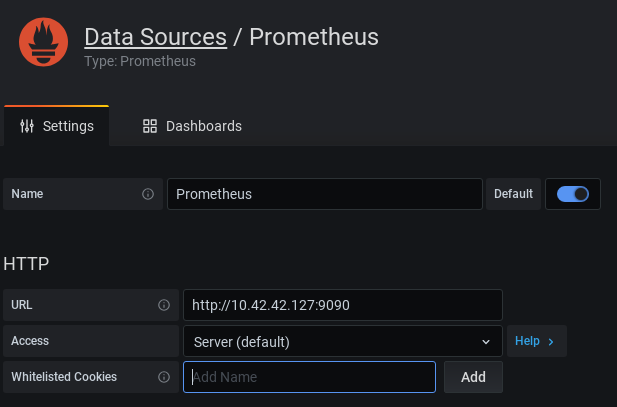
De retour sur la page d’accueil de Grafana, cliquer sur “Create your first dashboard” :
Cliquer sur “Create Panel“. Nous pourrons visualiser une première métrique collectée par Prometheus :
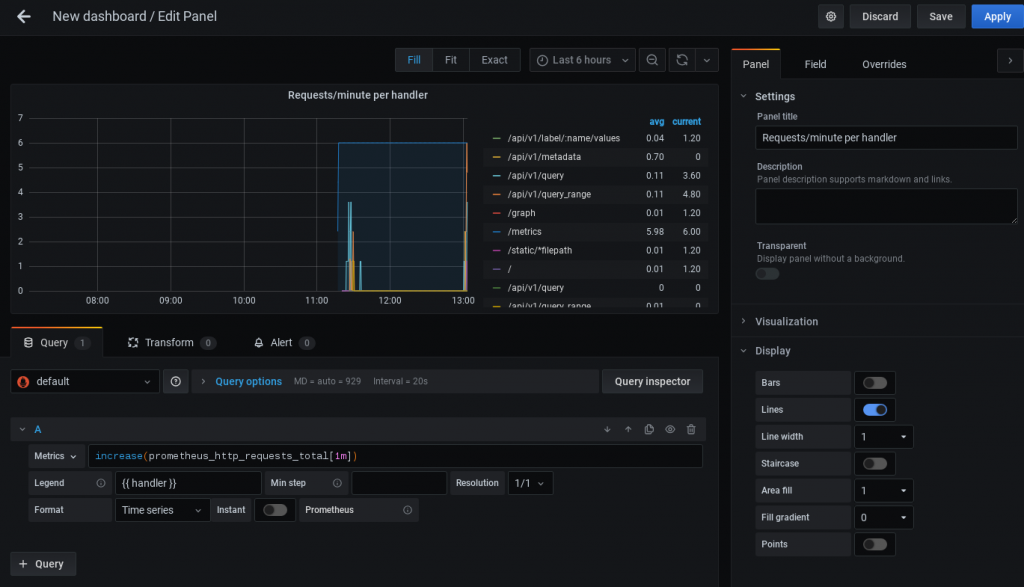
Rajouter d’autres visualisations, composant votre dashboard Prometheus :
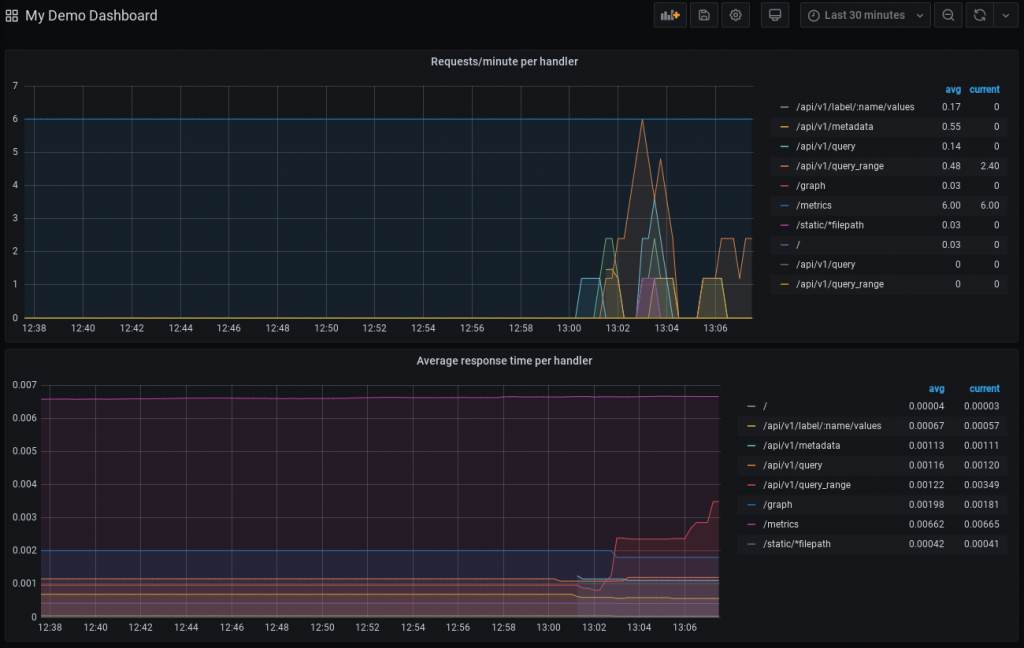
Notons qu’à ce stade, Grafana enregistre sa configuration dans une base SQlite, pour la quelle nous n’avons pas configuré de volume.
Vous l’aurez vu, la prise en main de Grafana est relativement simple, et plutôt ludique. La mise au point de visualisations se fait sans effort. D’autant plus que le site de Grafana propose une liste de dashboards communautaires, et beaucoup d’autres existent sur GitHub, GitLab, ou à portée de clic sur votre moteur de recherche préféré.
Thanos
Thanos est un outil s’appuyant sur le serveur Prometheus, remplissant plusieurs fonctions relatives à la centralisation et l’interrogation de métriques collectées par Prometheus, s’appuyant sur une solution de stockage type s3.
Thanos Sidecar
Nous l’avions mentionné plus tot, le serveur Prometheus pourra souffrir de l’accumulation de métriques sur de longs intervalles, sa consommation mémoire ou son disque n’étant pas limités.
Le Thanos Sidecar va lire la base TSDB de Prometheus, et interroge son API, pour retransmettre ses métriques vers un bucket s3. Par ailleurs, ce sidecar nous permettra d’agréger les données de plusieurs instances Prometheus, dans une unique solution de stockage distribuée.
Thanos Compact
Thanos dispose de sa propre rétention, Prometheus pourra se concentrer sur les derniers jours, ou dernières heures, réduisant ses besoins en mémoire. De même, Thanos Compact pourra sous-échantillonner nos séries, optimisant les temps de recherche, notamment sur de longues durées.
Thanos Store
Le Thanos Store implémente une paire d’interface Restfull et GRPC, servant les données collectées dans notre bucket s3, à d’autres composantes Thanos.
Thanos Query
Thanos Query permettra d’interroger nos métriques, émulant l’API et l’interface web de Prometheus.
Thanos Query renvoie ses requêtes aux différents Thanos Sidecar et à un Thanos Store, agrégeant leurs résultats – sans communication directe avec s3.
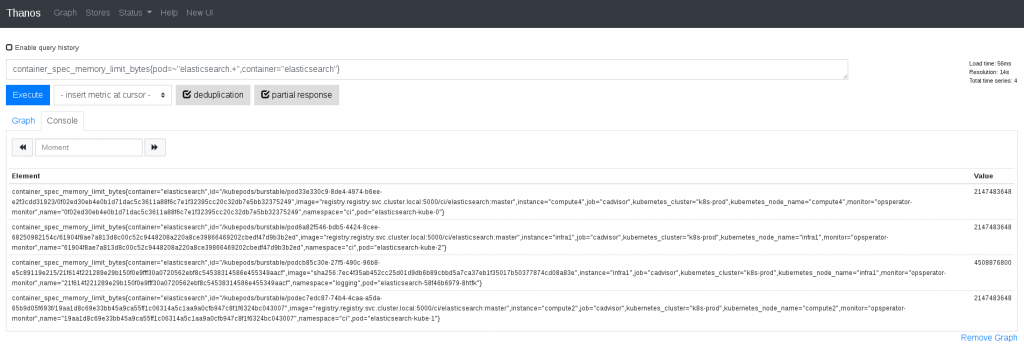
Thanos Query Console
Thanos Query Frontend
Le Thanos Query Frontend pourra se positionner devant Thanos Query, pour une mise en cache et sub-division des requêtes. Pour l’instant, le Query Frontend ne fonctionne que pour un type d’opération (query_range). Son action devant se généraliser, à plus long terme.
Thanos Receive
Nous pourrons utiliser Thanos Receive, pour les déploiements air-gapped de Prometheus, qui ne seraient pas adaptés au Thanos Sidecar. Soit faute de ne pouvoir contacter s3 directement, soit lorsque nos Thanos Query ne peuvent pas joindre un Thanos Sidecar – et donc, ne voient pas les dernières métriques collectées. Thanos Receive prendra alors en charge l’écriture dans notre bucket s3 de métriques poussées par Prometheus, tout en servant celles qui n’auraient pas été archivées aux clients de Thanos Query.
Thanos Rule
Thanos Rule pourra se substituer à Prometheus, dans son rôle d’évaluation de règles et identification d’alertes, pour retransmission à l’AlertManager.
La chose n’est pas nécessairement recommandée, le couple Prometheus / AlertManager remplit parfaitement cette fonction
À nouveau, il s’agit surtout de composer avec les réseaux restrictifs. Eventuellement de définir des tests interrogeant une longue période, pour laquelle la rétention de Prometheus ne suffirait plus.
Architecture d’un deploiement Prometheus, Thanos, Grafana
Ainsi, Thanos ne s’addresse pas à tout le monde. Il vient compléter l’écosystème Prometheus, pouvant souffrir d’un besoin en rétention ou granularité trop importants, d’un manque de disponibilité ou de continuité, sinon du service : des métriques servies.
Quant à Prometheus, dans un contexte où les solutions et produits “cloud-native” se multiplient, il saura composer tout type d’infrastructure, là où les acteurs historiques du secteur peuvent souffrir d’un manque d’adaptabilité. On appréciera par ailleurs l’architecture du produit, un découpage cohérent des fonctions, facilitant la redondance et la distribution de ses différents services.


