On a une base OpenLDAP avec 30 millions d’entrées, donc assez volumineuse. De temps en temps, pour des raisons techniques (mise à jour d’un service, par exemple), on doit basculer un état booléen sur toutes les entrées de façon à ce que ce service ne soit pas visible le temps de la mise à jour, puis revenir à l’état antérieur. Du fonctionnel, donc.
Les principes et objectifs
L’objectif de ce test est de déterminer la meilleure méthode pour conduire cette mise à jour, dans un contexte où des contraintes fortes de production sont présentes.
Pour cela nous allons tester plusieurs configurations tant matérielles que logicielles et mesurer les résultats obtenus, de façon à définir la configuration optimale.
L’architecture de réplication cible
On dispose de 4 serveurs identiques (32 Go de mémoire), avec OpenLDAP dans la version 2.6.10, en réplication complète (chaque serveur pouvant recevoir des modifications et les transmettre aux autres). La raison pour laquelle cette architecture a été choisie est de répartir la charge tout en s’assurant de la continuité de service si un ou plusieurs serveurs tombaient. La charge est importante, avec entre 100 000 à 300 000 modifications par jour (considérant que cette charge se répartit sur 10h, on tourne donc autour de 10 modifications par seconde).
Par ailleurs, ces serveurs reçoivent une charge de 30 000 recherches par seconde, ce qui est très important.
Le schéma suivant indique les relations de réplication :
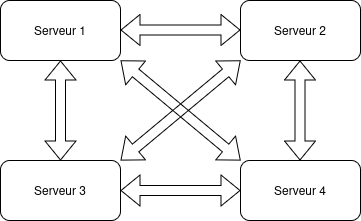
En terme de transferts, une modification appliquée sur un des serveurs est transmise plusieurs fois. Par exemple, la modification M appliquée sur le serveur S1 est transmise à S2, S3 et S4. Mais il faut aussi considérer que S2 transmet cette modification à S3 et S4, et de même pour chaque serveur. Au total, une modification est communiquée dans le pire des cas jusqu’à 9 fois avec 4 serveurs.
Note : La propagation s’arrête grâce à deux règles :
- On ne propage pas une entrée vers le serveur de provenance (par exemple, si S2 reçoit une entrée de S1, il ne la lui renvoie pas).
- On ne propage pas une entrée que l’on a déjà reçue (et pour cela on compare l’entryCSN local avec l’entryCSN de l’entrée reçue, s’ils sont égaux, la propagation de l’entrée cesse).
Avec d’aussi gros volumes de modifications potentielles, il est nécessaire d’utiliser delta-syncrepl, qui ne transfert que les attributs modifiés (et quelques autres attributs techniques), au lieu d’utiliser l’algorithme classique (syncrepl) qui transmet les entrées modifiées dans leur totalité.
Cela implique la mise en place d’une base de stockage des modifications partielles (accesslog), qui est utilisée en cas de reprise suite à une déconnexion d’un des serveurs. Cela signifie que chaque modification est appliquée localement, puis enregistrée dans accesslog, et envoyée aux serveurs en réplication.
On a donc une double écriture sur disque.
La contrainte supplémentaire est qu’il faut prévoir la purge de la base accesslog qui ne fait que grossir : idéalement, sur une base journalière, mais de préférence plus fréquemment pour éviter les gros traitements de purge (on parle de purger jusqu’à 300 000 modifications par jour, et 30 millions lors de l’opération qui nous intéresse).
La configuration testée
Pour les tests de charge, on va se contenter de configurer deux serveurs en MMR. Cela nous suffit pour mettre en évidence les problèmes potentiels et mesurer les performances dans différentes configurations.
De même, pour des raisons de temps de traitement, on teste les serveurs avec une base de données de 10 millions d’entrées, une extrapolation à 30 millions d’entrées sera effectuée.
La plateforme OpenStack a été configurée en conséquence, comme décrit dans l’article Construction d’une plateforme de test avec OpenStack.
Configuration OpenLDAP
Principes généraux
On configure donc deux serveurs disposant d’une base pour les données (worteks), et d’une base pour stocker les opérations à répliquer (accessLog).
Le mode de réplication utilisé est delta-syncrepl, qui optimise les données transmises en ne propageant que les valeurs d’attributs modifiées.
La base de configuration est également répliquée afin que les modifications apportées à chaud puissent se propager automatiquement aux autres serveurs.
La configuration en détail
La configuration se présente sous la forme d’une arborescence :
cn=config/
|
+-- cn=config.ldif
|
+-- cn=module{0}.ldif
|
+-- cn={0}schema/
|
+-- cn=schema.ldif
|
+-- olcDatabase={-1}frontend.ldif
|
+-- olcDatabase={0}config/
| |
| +-- olcOverlay={0}syncprov.ldif
|
+-- olcDatabase={0}config.ldif
|
+-- olcDatabase={1}monitor.ldif
|
+-- olcDatabase={2}mdb/
| |
| +-- olcOverlay={0}syncprov.ldif
|
+-- olcDatabase={2}mdb.ldif
|
+-- olcDatabase={3}mdb/
| |
| +-- olcOverlay={0}syncprov.ldif
| |
| +-- olcOverlay={1}accesslog.ldif
|
+-- olcDatabase={3}mdb.ldif
Les paragraphes suivants décrivent l’intégralité de la configuration.
cn=config
Voici le contenu de la configuration :
dn: cn=config
objectClass: olcGlobal
cn: config
# Les connections anonymes sont interdites
olcDisallows: bind_anon
# Localisation du fichier de log
olcLogFile: /var/log/openldap/slapd.log
# Sync + stats
olcLogLevel: 16640
olcRequires: authc
# Premier serveur
olcServerID: 11 ldap://openldap1:10389
# Second serveur
olcServerID: 12 ldap://openldap2:10389
cn=module{0}.ldif
Trois modules sont chargés :
- MDB
- AccessLog
- SyncProv
dn: cn=module{0}
objectClass: olcModuleList
cn: module{0}
# Chemin de stockage des modules
olcModulePath: /usr/local/openldap/libexec/openldap/
# Base mdb
olcModuleLoad: {0}back_mdb
# Provider de réplication
olcModuleLoad: {1}syncprov
# Base access log
olcModuleLoad: {2}accesslog
olcDatabase={-1}frontend.ldif
Cet élément de configuration ne contient aucune information globale dans notre plateforme de test.
dn: olcDatabase={-1}frontend
objectClass: olcDatabaseConfig
olcDatabase: {-1}frontend
olcDatabase={0}config.ldif
C’est dans cette entrée que l’on trouve les deux règles de réplication pour la configuration. La raison pour laquelle deux règles sont définies est que cela permet de copier cette configuration intégralement sur l’autre serveur : seules les règles qui ne correspondent pas au serveur local seront actives.
Note : Il faut faire attention à ce que les URLs utilisées comme valeur de l’attribut olcSyncrepl pour le paramètre provider correspondent exactement au paramètre -h passé en ligne de commande à slapd, sinon le serveur va chercher à répliquer vers lui-même. Par exemple, pour la ligne de commande de lancement de OpenLdap suivante :
$ slapd -h ldap://openldap1:10389 ...
il faut utiliser la configuration suivante pour olcSyncrepl :
olcSyncrepl: {0}rid=001 provider=ldap://openldap1:10389 ...
Si on utilise l’addresse IP de openldap1 dans cette ligne, la réplication du serveur vers lui-même sera activée…
Il est à noter que le mot de passe est en clair pour cet exemple, mais devrait techniquement être chiffré. Cela dit le mot de passe est également fourni en clair dans les directives de réplication, ce qui est nécessaire pour pouvoir s’authentifier sur le serveur distant. Une meilleure solution consiste à mettre en œuvre une authentification via certificats, pour éviter ce problème, mais cela sort du cadre de cette étude.
dn: olcDatabase={0}config
objectClass: olcDatabaseConfig
olcDatabase: {0}config
# Donne accès au user root
olcAccess: {0}to * by dn="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=a
uth" manage by dn="cn=admin,cn=config" manage by * none
olcRootDN: cn=admin,cn=config
# Mot de passe encodé en base 64 (ici : 'secret')
olcRootPW:: c2VjcmV0
# première directive de réplication de la configuration
olcSyncrepl: {0}rid=001 provider=ldap://openldap1:10389 binddn="cn=admin,cn=co
nfig" bindmethod=simple credentials="secret" searchbase="cn=config" type=refr
eshAndPersist retry="5 5 300 +" timeout=1
# seconde directive de réplication de la configuration
olcSyncrepl: {1}rid=002 provider=ldap://openldap2:10389 binddn="cn=admin,cn=co
nfig" bindmethod=simple credentials="secret" searchbase="cn=config" type=refr
eshAndPersist retry="5 5 300 +" timeout=1
# Autorise les updates sur ce serveur
olcMultiProvider: TRUE
olcDatabase={0}config/olcOverlay={0}syncprov.ldif
Cette entrée se contente de déclarer le module syncprov pour la base config.
dn: olcOverlay={0}syncprov
objectClass: olcSyncProvConfig
olcOverlay: {0}syncprov
olcDatabase={1}monitor.ldif
On définit les identifiants d’accès à la base monitor.
dn: olcDatabase={1}monitor
objectClass: olcDatabaseConfig
olcDatabase: {1}monitor
olcRootDN: cn=monitor
olcRootPW:: c2VjcmV0
olcDatabase={2}mdb.ldif
On définit ici la configuration de la base accesslog.
Un utilisateur spécifique doit être créé pour accéder à cette base. Son DN est uid=repl,ou=security,o=service,o=worteks.
Cette base est assez importante pour conserver une grande quantité de modifications, mais il faut la purger régulièrement. On verra quelle taille sera occupée après avoir appliqué 10 millions de modifications.
dn: olcDatabase={2}mdb
objectClass: olcDatabaseConfig
objectClass: olcMdbConfig
olcDatabase: {2}mdb
# Répertoire de stockage
olcDbDirectory: /usr/local/openldap/data/accesslog
# Le point d'entrée de la base
olcSuffix: cn=accesslog
# Accès autorisé au user uid=repl
olcAccess: {0}to * by dn.base="uid=repl,ou=security,o=service,o=worteks" read by * break
# Cet utilisateur n'a pas de restriction
olcLimits: {0}dn="uid=repl,ou=security,o=service,o=worteks" size=unlimited time=unl
imited
# La base est read only (seul le serveur y écrira)
olcReadOnly: TRUE
# Le root user
olcRootDN: cn=accesslog
# et son mot de passe ('secret')
olcRootPW:: c2VjcmV0
# Stocke le ContextCSN dans une subentry cn=ldapsync
olcSyncUseSubentry: TRUE
# La base est monitorée
olcMonitoring: TRUE
# Écrit les données toutes les minutes en base
olcDbCheckpoint: 0 1
# Les données ne sont pas immédiatement écrites sur disque
olcDbNoSync: TRUE
# Les index déclarés
olcDbIndex: default eq
olcDbIndex: entryCSN,objectClass,reqEnd,reqResult,reqStart,reqDN,reqSession
# Taille maximale de la base, ici 40Go
olcDbMaxSize: 40000000000
# Nombre d'entrées maximales traitées par un search
olcDbRtxnSize: 10000
olcDatabase={2}mdb/olcOverlay={0}syncprov.ldif
Cette entrée déclare le module syncprov pour la base accesslog.
La particularité est que l’on positionne le flag olcSpNoPresent à TRUE car on ne souhaite pas que la phase ‘present’ de l’algorithme de réplication soit activée. Cette phase permet de déterminer les entrées qui ont été supprimées sur le serveur distant, pour pouvoir les supprimer localement. Cela n’a pas de sens pour une base de log.
Le flag olcSpReloadHint doit être positionné à TRUE pour la base accesslog. Cela force une mise à jour au redémarrage de la réplication.
dn: olcOverlay={0}syncprov
objectClass: olcSyncProvConfig
olcOverlay: {0}syncprov
# La phase 'present' de la réplication est désactivée.
olcSpNoPresent: TRUE
olcSpReloadHint: TRUE
olcDatabase={3}mdb.ldif
Cette entrée définit la configuration de la base de données proprement dite.
On y décrit les ACLs (règles d’accès), les limites, l’utilisateur d’administration (dont le mot de passe est en clair ici, mais devra être haché en production), les directives de réplication.
Concernant ces dernières, on en a autant qu’il y a de serveurs présents dans l’architecture MMR, sachant que celle correspondant au serveur lui-même sera ignorée. Ici, on a deux directives, une seule sera activée.
Leur configuration indique :
- L’identifiant de réplication (RID) utilisé par le client pour identifier la réplication. Dans notre cas on a 2 serveurs, le local et le distant, donc il y a deux lignes olcSyncrepl avec deux RID différents. Il est à noter qu’on réplique également la configuration, donc il faut faire attention à ce que les RID soient différents de ceux utilisés pour la configuration.
- L’URL du serveur à contacter
- L’utilisateur de réplication : uid=repl,ou=security,o=service,o=worteks
- La base accesslog à utiliser : cn=accesslog
- Le filtre sur cette base, à savoir les objets en update (objectClass=auditWriteObject) et qui ont été validés (reqResult=0). A noter que, comme la base a été configurée pour ne stocker que les modifications réussies, ce dernier filtre n’est pas nécessaire.
- Le type de réplication (refreshAndPersist) : on se connecte, on rafraîchit la base puis on reste à l’écoute de toute mise à jour indéfiniment
- Les directives retry en cas de déconnexion, ici toutes les 5 secondes sans interruption
- Le temps d’attente maximum pour valider la connexion à un serveur distant, ici 1 seconde
- Le format des données reçues, ici avec le paramètre syncdata=accesslog, on ne recevra que les différences entre l’entrée initiale et l’entrée modifiée.
La base est MultiProvider, ce qui signifie que le serveur pourra recevoir des modifications.
Elle est configurée pour ne pas écrire les données immédiatement sur le disque, pour des raisons de performances (olcDbNoSync à TRUE). Les données sont alors écrites sur disque quand plus de 1Mo de données ont été reçues, ou qu’une minute s’est écoulée. Le risque de perte en cas de crash est faible.
dn: olcDatabase={3}mdb
objectClass: olcDatabaseConfig
objectClass: olcMdbConfig
olcDatabase: {3}mdb
# Le répertoire de stockage des données
olcDbDirectory: /usr/local/openldap/data/worteks/
# Le DN de la racine
olcSuffix: o=service,o=worteks
# Autorise l'utilisateur root à se connecter
# ainsi que l'utilisateur de réplication en read only
# Les utilisateurs anonymes sont rejetés
olcAccess: {0}to * by dn="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=a
uth" read by dn="uid=repl,ou=security,o=service,o=worteks" read by anonymous a
uth by * none break
# L'attribut userPassword n'est jamais accessible
olcAccess: {1}to attrs=userPassword by * none
# La branche ou=security n'est pas accessible
olcAccess: {2}to dn.subtree="ou=security,o=service,o=worteks" by * none
olcAccess: {3}to * by * none
# Les entrées ajoutées seront contrôlées avec les ACLs
olcAddContentAcl: TRUE
# L'utilisateur de réplication n'a pas de limite
olcLimits: {0}dn="uid=repl,ou=security,o=service,o=worteks" size=unlimited tim
e=unlimited
# L'utilisateur root n'a pas de limite
olcLimits: {1}dn="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=auth" siz
e=unlimited time=unlimited
# DN de l'administrateur de la base
olcRootDN: cn=admin,o=service,o=worteks
# Password en clair ('secret')
olcRootPW:: c2VjcmV0
# Première directive de réplication
olcSyncrepl: {0}rid=012 provider=ldap://openldap1:10389 binddn="uid=repl,ou=se
curity,o=service,o=worteks" bindmethod=simple credentials="secret" searchbase
="o=service,o=worteks" logbase="cn=accesslog" logfilter="(&(objectClass=audit
WriteObject)(reqResult=0))" type=refreshAndPersist retry="5 +" timeout=1 sync
data=accesslog
# Seconde directive de réplication
olcSyncrepl: {1}rid=011 provider=ldap://openldap2:10389 binddn="uid=repl,ou=se
curity,o=service,o=worteks" bindmethod=simple credentials="secret" searchbase
="o=service,o=worteks" logbase="cn=accesslog" logfilter="(&(objectClass=audit
WriteObject)(reqResult=0))" type=refreshAndPersist retry="5 +" timeout=1 sync
data=accesslog
# Serveur en MMR
olcMultiProvider: TRUE
# Les données sont écrites chaque minute
olcDbCheckpoint: 0 1
# Pas d'écriture sur disque immédiate
olcDbNoSync: TRUE
# Les index à déclarer
olcDbIndex: entryUUID eq
olcDbIndex: objectClass eq
olcDbIndex: entryCSN eq
olcDbIndex: uid eq
olcDbIndex: mailboxServiceIMAP eq
olcDbIndex: mailboxServicePOP eq
olcDbIndex: mailPrimaryAddress eq
olcDbIndex: mailAlternativeAddress eq
olcDbIndex: mailboxHiddenAlias eq
# Taille maximale de la base, 80Gb
olcDbMaxSize: 85899345920
olcDatabase={3}mdb/olcOverlay={0}syncprov.ldif
La configuration de l’overlay syncprov pour la base de données spécifie une taille de log en mémoire de 10 000 opérations pour éviter de lire dans la base accesslog si une déconnexion courte a lieu. On n’écrit l’attribut contextCSN qu’une fois toutes les 100 opérations ou toutes les 10 minutes, ce qui évite des écritures trop fréquentes. Avec 300 000 modifications par jour (réparties sur 10h), cela représente 500 mises à jour par minute, donc 5 mises à jour des données par minute pendant la journée, et une modification toutes les 10 minutes hors période d’activité. C’est un compromis acceptable, mais il est possible d’augmenter le nombre de modifications à appliquer avant mise à jour du contextCSN à 500 pour qu’il ne soit effectué qu’une fois par minute.
dn: olcOverlay={0}syncprov
objectClass: olcSyncProvConfig
olcOverlay: {0}syncprov
# Le _contextCSN_ n'est écrit sur disque que toutes les 100 opérations ou 10 minutes
olcSpCheckpoint: 100 10
# Taille de la session conservée en mémoire, ici 10 000 opérations
olcSpSessionlog: 10000
olcDatabase={3}mdb/olcOverlay={1}accesslog.ldif
La configuration de l’overlay accesslog utilisé pour la réplication de la base de données :
dn: olcOverlay={1}accesslog
objectClass: olcAccessLogConfig
olcOverlay: {1}accesslog
# Pointe vers la base accesslog à utiliser
olcAccessLogDB: cn=accesslog
# Ne garde que les opérations d'écriture (add, delete, modify, moddn)
olcAccessLogOps: writes
# Garde les entrées un maximum de 7 jours, et effectue la purge tous les jours
olcAccessLogPurge: 07+00:00 01+00:00
# Ne garde que les opérations ayant réussi
olcAccessLogSuccess: TRUE
La préparation des données
Les tests effectués montrent qu’on peut appliquer jusqu’à 2000 modifications par seconde avec un serveur disposant de 8 Go de mémoire. Il faut donc 1h30 pour les appliquer toutes dans le cas des 10 millions de modifications (10 000 000 modifications / 2000 par seconde / 3600 secondes par heure -> 1h 23mins)
Bien évidemment, cela dépend de l’infrastructure physique. La base utilisée est MDB, qui n’accepte pas d’écriture concurrente, donc une écriture en base ne pourra se faire que quand la précédente aura été effectuée. Le facteur important concernant les performances est la taille mémoire disponible : l’objectif est que la totalité de la base MDB soit montée en mémoire. On analysera le comportement de la base quand ce n’est pas le cas.
Chaque entrée contient de nombreux attributs et, ceux-ci pouvant être indexés, il convient d’étudier la base chargée avec un nombre significatif d’entrées pour estimer sa taille.
En utilisant la commande _mdb_stat -a
$ mdb_stat -a /usr/local/openldap/data/worteks
Status of Main DB
Tree depth: 1
Branch pages: 0
Leaf pages: 1
Overflow pages: 0
Entries: 14
Total: 4Ko
Status of ad2i
Tree depth: 1
Branch pages: 0
Leaf pages: 1
Overflow pages: 0
Entries: 35
Total: 4Ko
Status of dn2i
Tree depth: 4
Branch pages: 594
Leaf pages: 133335
Overflow pages: 0
Entries: 20000013
Total: 4096 * (594 + 133 335) = 536 Mo
Status of entryCSN
Tree depth: 3
Branch pages: 55
Leaf pages: 13596
Overflow pages: 0
Entries: 10000006
Total: 4096 * (55 + 13 596) = 54 Mo
Status of entryUUID
Tree depth: 4
Branch pages: 451
Leaf pages: 77171
Overflow pages: 0
Entries: 10000006
Total = 4096 * (451 + 77 171) = 310 Mo
Status of id2e
Tree depth: 4
Branch pages: 29118
Leaf pages: 4935050
Overflow pages: 0
Entries: 10000006
Total = 4096 * (29 118 + 4 935 050) = 19,9 Go
Status of id2v
Tree depth: 0
Branch pages: 0
Leaf pages: 0
Overflow pages: 0
Entries: 0
Total: 0
Status of ixck
Tree depth: 0
Branch pages: 0
Leaf pages: 0
Overflow pages: 0
Entries: 0
Total: 0
Status of mailAlternativeAddress
Tree depth: 4
Branch pages: 453
Leaf pages: 77987
Overflow pages: 0
Entries: 10000000
Total = 4096 * (453 + 77 987) = 314 Mo
Status of mailPrimaryAddress
Tree depth: 4
Branch pages: 441
Leaf pages: 77862
Overflow pages: 0
Entries: 10000000
Total = 4096 * (441 + 77 862) = 313 Mo
Status of objectClass
Tree depth: 1
Branch pages: 0
Leaf pages: 1
Overflow pages: 0
Entries: 36
Total = 4 Ko
Status of MailboxHiddenAlias
Tree depth: 4
Branch pages: 448
Leaf pages: 77683
Overflow pages: 0
Entries: 10000000
Total = 4096 * (448 + 77 683) = 313 Mo
Status of MailboxServiceIMAP
Tree depth: 1
Branch pages: 0
Leaf pages: 1
Overflow pages: 0
Entries: 3
Total = 4 Ko
Status of MailboxServicePOP
Tree depth: 1
Branch pages: 0
Leaf pages: 1
Overflow pages: 0
Entries: 3
Total = 4 Ko
Status of uid
Tree depth: 4
Branch pages: 465
Leaf pages: 77931
Overflow pages: 0
Entries: 10000001
Total = 4096 * (465 + 77 931) = 313 Mo
Cette base occupe donc 19,9 Go pour les données (table id2e), 1,6 Go pour les index et 0,5 Go pour les DNs, soit un total d’environ 22 Go.
On peut croiser cette information avec les données récupérées avec la commande _mdb_stat -e
$ mdb_stat -e /usr/local/openldap/data/worteks
Environment Info
Map address: (nil)
Map size: 137438953472
Page size: 4096
Max pages: 33554432
Number of pages used: 5650219
Last transaction ID: 9691279
Max readers: 126
Number of readers used: 7
Status of Main DB
Tree depth: 1
Branch pages: 0
Leaf pages: 1
Overflow pages: 0
Entries: 14
On constate qu’il y a 5 650 219 pages utilisées, avec une taille de 4 Ko par page, soit un total de 22,6 Go.
Le chiffre diffère légèrement, car il y a des pages libres qui seront réutilisées dans le retour de la seconde commande. On retiendra la taille de 23 Go par sécurité.
A ce chiffre, il faut ajouter la place occupée par la base access_log après injection de 10 millions de modifications :
Environment Info
Map address: (nil)
Map size: 137438953472
Page size: 4096
Max pages: 33554432
Number of pages used: 1511239
Last transaction ID: 4811538
Max readers: 126
Number of readers used: 5
Status of Main DB
Tree depth: 1
Branch pages: 0
Leaf pages: 1
Overflow pages: 0
Entries: 12
Pour 1 511 239 pages de 4 Ko, cela correspond à 6 Go supplémentaires.
On considère donc qu’avec 23 Go + 6 Go, soit 29 Go, une taille mémoire de 32 Go permet de conserver la totalité de la base en mémoire, ce qui évitera des I/O lors de la mise à jour des B-tree. En effet, si on dispose d’une taille mémoire inférieure, il y aura nécessairement des lectures de pages sur disque pour remonter la structure et les feuilles en mémoire. En pratique, moins on dispose de mémoire, plus il y a d’entrées sorties et donc de ralentissements.
Voici par exemple ce que prend l’injection de 10 millions d’entrées selon la taille mémoire affectée au serveur (le fichier contenant les entrées fait 9,4 Gb) :
+----------------+-------------------+----------+
| Taille mémoire | Temps d'injection | Entrée/s |
+----------------+-------------------+----------+
| 2Gb | 11h 37m | 239/s |
+----------------+-------------------+----------+
| 3Gb | 1h 39m 55s | 1668/s |
+----------------+-------------------+----------+
| 3.5Gb | 36m 59s | 4625/s |
+----------------+-------------------+----------+
| 4Gb | 8m 50s | 18 867/s |
+----------------+-------------------+----------+
| 8Gb | 8m 20s | 20 000/s |
+----------------+-------------------+----------+
| 16Gb | 7m 08s | 23 364/s |
+----------------+-------------------+----------+
| 32Gb | 7m 41s | 24 390/s |
+----------------+-------------------+----------+
Jusqu’à un certain point, le manque de mémoire est pénalisant lors de l’injection de données dans la base, puis rajouter de la mémoire n’améliore que marginalement les temps d’exécution. L’inflexion est assez brutale.
Si on considère l’index de l’attribut entryUUID, dont les données sont les suivantes :
Status of entryUUID
Tree depth: 4
Branch pages: 451
Leaf pages: 77171
Overflow pages: 0
Entries: 10000006
on constate que le nombre de pages intermédiaires ne représente que 0,6% des pages utilisées pour cet index. Le ratio est le même pour la table id2e qui contient les entrées. Plus on dispose de mémoire, plus on augmente la probabilité que les pages intermédiaires soient présentes en mémoire. Cela limite les I/O disque, augmentant les performances de plusieurs ordres de magnitude. C’est ce qu’on constate dès 3 Gb de mémoire.
Par contre, il s’agit d’un scénario d’écriture où les données sont écrites séquentiellement, qui n’est pas représentatif d’un fonctionnement normal d’une base LDAP. Dans un scénario de lecture où les données lues se répartiront aléatoirement sur l’ensemble des pages, ce niveau de mémoire va entraîner de nombreuses lectures de pages terminales. Il convient, dans la mesure du possible, de monter la totalité des pages en mémoire et donc d’augmenter celle-ci pour correspondre à la taille totale de la base de données. Pour une base de 30 millions d’entrées, on peut considérer que 32 Gb de mémoire sont suffisants pour l’injection, mais insuffisants pour monter la totalité de la base en mémoire. En extrapolant les chiffres obtenus pour 10 millions d’entrées, on peut estimer qu’il faut 96 Gb de mémoire (32 Gb x 3 pour un triplement du nombre d’entrées) pour s’assurer que toute la base sera en mémoire à terme et ainsi obtenir la meilleure performance possible en lecture et en écriture.
La copie des données
Dans notre cas, on va utiliser des serveurs disposant de 16 Go de mémoire, dont les bases de données et accesslog ont été supprimées au préalable.
Le nettoyage des bases se fait de la façon suivante :
$ cd /usr/local/openldap/data
$ rm accesslog/*
$ rm worteks/*
Cette suppression doit s’effectuer sur les deux serveurs.
On va ensuite charger deux jeux de données :
- La base, qui construit l’arborescence. Il s’agit d’une dizaine d’entrées. La commande suivante effectue ce travail :
$ slapadd -b "o=service,o=worteks" -F /usr/local/openldap/etc/openldap/slapd.d -l /home/debian/base.ldif -S 11
- Les données, soit 10 millions d’entrées avec une structure telle que :
dn: uid=<UID>,cn=mailboxes,ou=fr,o=service,o=worteks
objectClass: inetOrgPerson
objectClass: mailbox
objectClass: simpleSecurityObject
objectClass: uidObject
cn: cn<UID>
sn: sn<UID>
uid: <UID>
userPassword:: MDAwMDAwMDAwMA==
displayName: displayName<UID>
givenName: givenName<UID>
mailAlternativeAddress: alias<UID>@worteks.fr
mailPrimaryAddress: <UID>@worteks.fr
mailboxAccountStatus: active
mailboxDomainId: 1
mailboxGroupName: RETAIL
mailboxHiddenAlias: hiddenAlias<UID>@worteks.fr
mailboxQuota: 10737418240
mailboxServiceAntivirusAll: FALSE
mailboxServiceIMAP: FALSE
mailboxServicePOP: FALSE
mailboxServiceSMTPIn: TRUE
mailboxServiceSMTPOut: TRUE
mailboxServiceWebmail: TRUE
mailboxSite: 1
mailboxStorage: 0
mailboxUserOidVal: MELOFR-200-MDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMA==
mailboxUserServiceOidVal: 0030003000300030003000300030003000300030
Une entrée comporte 24 attributs et les attributs suivants sont indexés :
- entryUUID
- objectClass
- entryCSN
- uid
- mailboxServiceIMAP
- mailboxServicePOP
- mailPrimaryAddress
- mailAlternativeAddress
- mailboxHiddenAlias
ATTENTION!!! Si les injections de données se font avec le user root, la base de données n’aura pas les bons droits et ne pourra pas être chargée au démarrage de slapd. Il conviendra de faire un chown ldap:ldap /usr/local/openldap/data/worteks/* avant le lancement de slapd.
L’injection se fait via la commande :
$ slapadd -q -w -s -b "o=service,o=worteks" -F /usr/local/openldap/etc/openldap/slapd.d -l /tmp/entries.ldif -S 11
Les options utilisées pour ce premier import sont les suivantes :
- -q : Quick mode. On suppose que les données sont correctes.
- -w : Une fois toutes les entrées injectées, le contextCSN va être mis à jour avec l’entryCSN le plus récent (donc celui de la dernière valeur injectée)
- -s : Pas de vérification du schéma
- -S : L’identifiant du serveur, ServerID, ici 11
Une fois l’injection initiale effectuée sur un des serveurs, il faut exporter les données et les recharger sur les autres serveurs.
On commence par exporter les données du premier serveur par la commande suivante :
$ slapcat -b "o=service,o=worteks" -F /usr/local/openldap/etc/openldap/slapd.d -l /tmp/all.ldif
On déplace le résultat sur le second serveur, puis on injecte les données par la commande suivante :
$ slapadd -b "o=service,o=worteks" -F /usr/local/openldap/etc/openldap/slapd.d -l /tmp/all.ldif -q -s
Ici, on utilise également les options -q (pas de vérification) et -s (pas de contrôle du schéma), mais pas l’option -w. L’option -S permet de donner le serverID.
L’opération prend environ 7 minutes sur ce serveur, comme précédemment.
A ce stade, les deux serveurs contiennent les mêmes informations, toutes avec la même date. Les bases sont donc équivalentes.
On le vérifie après relance des deux serveurs OpenLDAP :
# slapd-cli start
slapd-cli: [INFO] Using /usr/local/openldap/etc/openldap/slapd-cli.conf for configuration
slapd-cli: [INFO] Launching OpenLDAP configuration test...
slapd-cli: [OK] OpenLDAP configuration test successful
slapd-cli: [INFO] Launching OpenLDAP...
slapd-cli: [OK] File descriptor limit set to 1024
slapd-cli: [ALERT] No PID file for OpenLDAP
Même opération sur le second serveur.
Comme on est en delta-syncrepl, il faut déclencher la réplication, ce qui se fait en effectuant une modification sur le premier serveur, ce qui synchronise les deux bases. La raison pour laquelle cette étape est nécessaire est que le mécanisme de réplication s’appuie sur le contenu de la base accesslog, qui est vide. Cela permet de diffuser les contextCSN sur chaque serveur.
Normalement, on doit retrouver le contextCSN des deux serveurs sur chaque serveur.
Sur OpenLDAP1 :
20250625130822.612684Z#000000#000#000000
20250625135436.855194Z#000000#00c#000000 -> Serveur ID 12 ('0x0b' en troisième position)
20250625135502.701625Z#000000#00b#000000 -> Serveur ID 11 ('0x0c' en troisième position)
Sur OpenLDAP2 :
20250625130822.612684Z#000000#000#000000
20250625135502.701625Z#000000#00b#000000 -> Serveur ID 11 ('0x0b' en troisième position)
20250625135922.024564Z#000000#00c#000000 -> Serveur ID 12 ('0x0c' en troisième position)
On est prêt pour l’étape suivante.
Injection des modifications
On va donc appliquer une modification sur 10 millions d’entrées. Cette modification va être générée par un script prenant comme template ce fichier :
DN: uid=<UID>,cn=mailboxes,ou=fr,o=service,o=worteks
changetype: modify
replace: mailboxServiceAntivirusAll
mailboxServiceAntivirusAll: TRUE
qui va être appliquée via un ldapModify à toutes les entrées, le résultat étant stocké dans le fichier mod.ldif. On boucle pour remplacer l’UID par la valeur de chaque entrée.
La commande est la suivante :
ldapmodify -x -H ldap://openldap1:10389 -D "cn=admin,o=service,o=worteks" -w secret -f mod.ldif
Sur les serveurs de test, cela applique environ 2200 modifications par seconde. Il faut donc environ 1h30 pour que toutes les modifications soient appliquées et répliquées. Sur une base de 30 millions d’entrées, cela va prendre près de 5h.
Il est à noter qu’en modifiant le paramètre olcDbNoSync de TRUE à FALSE, l’injection se fait au rythme de 250 modifications par seconde, soit environ 9 fois plus lentement!
La raison étant que les données sont écrites lors de chaque modification, ralentissant fortement le traitement. La contrepartie en production, c’est qu’il y a un risque de perte de données, si le serveur est arrêté brutalement.
Ce risque est compensé par le fait qu’il faudrait l’arrêt de l’ensemble des serveurs simultanément pour que les données ne soient pas enregistrées, la réplication étant déclenchée dès l’enregistrement local des données sur un serveur.
Est-il possible d’améliorer ce temps d’injection ? En pratique, il est possible de basculer sur une commande passée serveur arrêté, slapmodify.
La seconde solution consiste à arrêter les bases, appliquer les modifications avec un slapmodify, exporter la base avec un slapcat, copier l’export sur les différents serveurs, les recharger avec un slapadd après avoir purgé les bases, redémarrer les serveurs et faire une modification sur un des serveurs pour relancer la réplication.
Ces opérations prennent un peu moins d’une heure (slapmodify : 10 minutes, slapcat : 10 minutes, slapadd sur les serveurs : 10 minutes, plus le temps de copie et les manipulations), mais peuvent être scriptées. Il s’agit néanmoins d’une opération qui se mène à froid, ce qui interrompt le service pendant sa durée. Il est néanmoins possible de limiter la durée de coupure à 10 minutes, le temps nécessaire pour appliquer localement les modifications. La manipulation est plus complexe, il faut relancer le serveur après application des modifications, puis faire un ldapsearch à chaud, et injecter le résultat dans la seconde base qui, elle, a été maintenue arrêtée. Une fois ces manipulations terminées, on peut relancer le second serveur, qui se met à jour avec le premier.
Une alternative serait de garder les serveurs clients en lecture seule, réplication désactivée, le temps que la mise à jour des données et l’export soient effectués sur le premier serveur, suivi d’un redémarrage du serveur à jour, avec arrêt des serveurs clients, mise à jour de ceux-ci et redémarrage. Dans ce scénario, on n’aura qu’un service dégradé le temps de la mise à jour, mais accessible en lecture.
Conclusion
OpenLDAP est une base performante, mais qui nécessite une attention particulière aux paramètres de configuration dès qu’on y stocke des données volumineuses. Une base de 30 millions d’entrées n’est pas un cas d’usage fréquent et il convient d’anticiper les opérations de maintenance.
La taille de la mémoire allouée est le paramètre le plus crucial quand il s’agit d’obtenir les meilleures performances. Économiser sur la configuration physique est une garantie de surcoût à brève échéance. Dans le cas d’écritures nombreuses, il est également critique de disposer d’un support physique rapide (SSD ou NVMe) et de se poser la question de l’arbitrage entre risque de perte et rapidité (on a vu qu’un facteur 9 en performance est à payer si on souhaite s’assurer d’écritures atomiques).
Les autres éléments de configuration (index, structure de la base, ACLs, attributs multi-valués avec de nombreuses valeurs, etc) peuvent également impacter les performances, mais dans une moindre mesure. Ils pourront faire l’objet d’autres études.