
Les projets de science de la donnée nécessitent souvent une analyse exploratoire et des logiciels spécifiques comme des notebooks. De plus, les bonnes pratiques encouragent les scientifiques de la donnée à s’assurer de la reproductibilité de leurs études. Par ailleurs, correctement gérer les ressources d’un cluster dans le cloud peut s’avérer complexe et fastidieux sans solution d’orchestration et de gestion des ressources. C’est pourquoi utiliser Kubernetes pour les projets de Science de la donnée, par opposition à des outils plus classiques comme Slurm, peut être judicieux. Nous allons voir comment installer Open Data Hub, une solution d’orchestration basée sur OpenShift pour les projets de science de la donnée.
Installation de l’opérateur Open Data Hub
Pour installer l’opérateur OpenShift responsable du déploiement et de la gestion d’Open Data Hub, se rendre sur Operators → OperatorHub et chercher “Open Data Hub”, puis cliquer sur Install. Vérifier que la version utilisée soit bien la version stable, la version 1.5.0 à la date de rédaction de cet article.
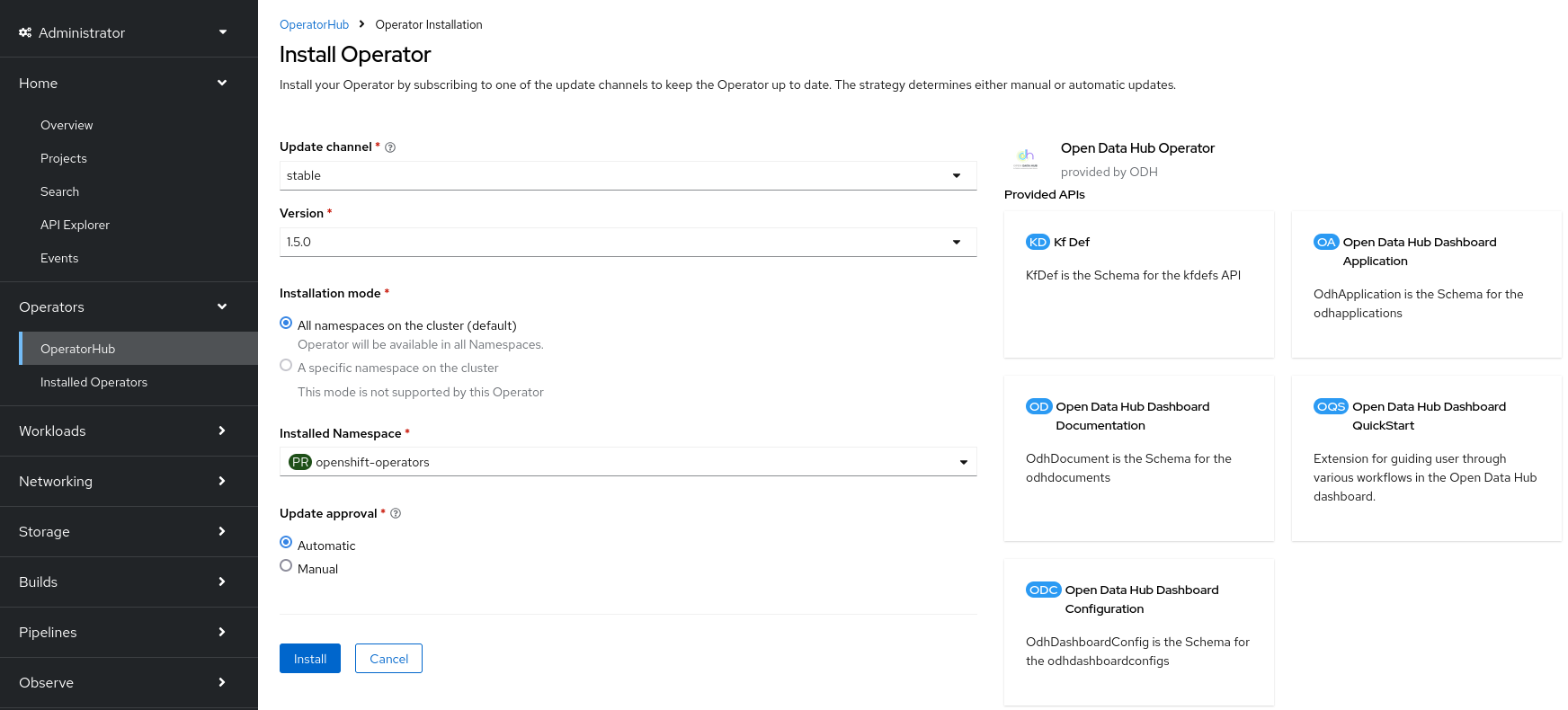
Une fois l’opérateur Open Data Hub installé, créer un projet opendatahub qui
contiendra les ressources qui y sont liées:
vincent@fedora ~> oc new-project opendatahub
Now using project "opendatahub" on server "https://okd:6443".
Manifestes de déploiement
L’opérateur déploie Open Data Hub par le biais de manifestes téléchargés depuis
ce dépôt git pour les
versions d’Open Data Hub ≤ 1.10.0. Ces manifestes peuvent être changés en
modifiant les fichiers YAML, pour obtenir une personnalisation fine des
paramètres d’installation. Par exemple, il est possible de
modifier les registres utilisés pour les images des pods composant Open Data
Hub, comme openshift4/ose-oauth-proxy ou rhel7/etcd.
Pour cela, faire un clone local du dépôt git ou un fork directement sur GitHub.
Une fois les modifications effectuées, il faut héberger la nouvelle version sur
une URL accessible depuis le cluster OpenShift, dans un format compréhensible
par
go-getter,
comme par exemple une archive .zip ou .tar.gz sur une adresse HTTPS.
Déploiement d’Open Data Hub et utilisation
Pour déployer Open Data Hub, se rendre sur Installed Operators → Open Data
Hub, et sélectionner le projet opendatahub depuis la liste déroulante listant
les projets. Ensuite, se rendre dans l’onglet Kf Def et cliquer sur Create
KfDef pour ouvrir le formulaire de déploiement d’Open Data Hub.
Le formulaire va configurer la création d’une instance, c’est à dire un
regroupement de ressources OpenShift telles que des ConfigMap, des Secret,
des Deployement ou des Service. Le formulaire permet d’activer ou de
désactiver les applications composant Open Data Hub qui seront installées via la
partie applications. La partie repos permet elle de sélectionner les
manifestes qui seront déployés.
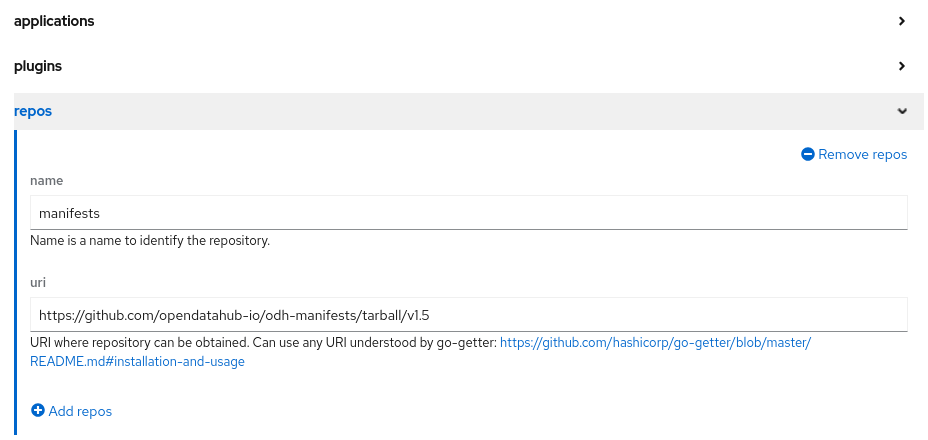
Une fois le formulaire renseigné, appuyer sur le bouton Create. Pour accéder à Open Data Hub, se rendre dans la Partie Networking → Route pour obtenir l’URL du tableau de bord.
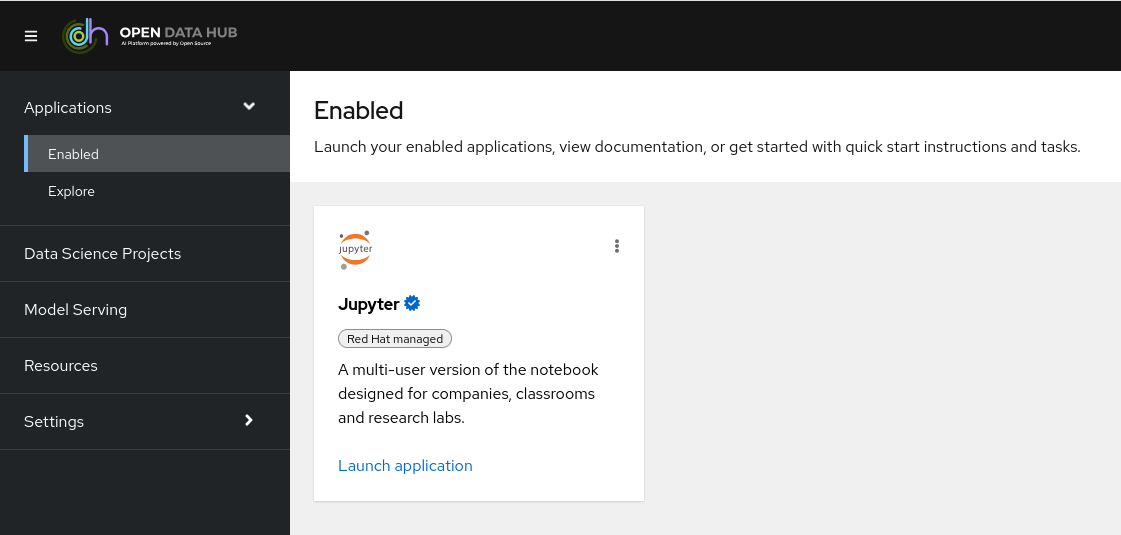
Pour tester le bon fonctionnement d’Open Data Hub, créer un projet Data Science
en se rendant dans la partie Data Science Projects, puis créer une nouvelle
Workbench. Sélectionner une image parmi celle pré-installées ainsi que le
dimensionnement du conteneur en termes de requests et limits Kubernetes, et
le stockage. Les images pré-installées contiennent des logiciels spécifiques à
la science de la donnée. Une fois les paramètres choisis, appuyer sur Create
workbench. Cela va automatiquement lancer un pod avec les paramètres
choisis, permettant par exemple de démarrer un notebook
Jupyter. Une fois la workbench démarrée, appuyer sur
Open pour ouvrir l’interface web de la workbench en fonction de l’image
choisie. Si l’image est celle de Jupyter, l’interface de Jupyter s’affiche.
Les utilisateurs d’Open Data Hub qui sont membres de cluster-admin sur
OpenShift ont des droits administrateurs qui permettent d’accéder aux options
d’Open Data Hub. Il est par exemple possible d’importer et configurer d’autres
images pour les workbenches, afin de donner l’accès à d’autres logiciels au sein
des notebooks.
Open Data Hub permet ainsi de provisionner automatiquement des espaces de travail compartimentés pour les scientifiques de la donnée, en accord en avec les bonnes pratiques en matière de reproductibilité, de compartimentation et de gestion des ressources.
N’hésitez pas à nous contacter pour une présentation des capacités d’Open Data Hub adaptée à vos besoins ou pour connaître nos solutions d’hébergement souverain pour le calcul scientifique et l’intelligence artificielle.



